马上注册,享用更多功能,让你轻松玩转AIHIA梦工厂!
您需要 登录 才可以下载或查看,没有账号?立即注册
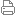
x
相关源码可参考最新的实现:https://github.com/ronnyyoung/EasyML ,中的neural_network模块,后持续更新,包括加入CNN的结构。
一、引言在前一篇关于神经网络的文章中,给出了神经网络中单个神经元的结构和作用原理,并且用梯度下降的方法推导了单个SIMGOID单元的权值更新法则。在文章的最后给了一个例子,我们以一个4维的单位向量作为特征,映射到一维的[0,1]的空间中,我们采用了一个感知器单元,实验结果发现经过15000次(实际应该在5000次左右已经收敛了)的训练后,对于给出的特征向量,感知器单元总是能够得到很接近我们预期的结果了。然而在实际应用过程中,单个神经元不能拟合太复杂的映射关系,我们需要构建更复杂的网络来逼近那些更复杂的目标函数,本文的最后,我们会用多层网络处理前一篇文章中的例子,经过300-500次的训练,就可以很好的收敛。 本篇文章为神经网络这个主题的第二篇文章,主要介绍多层网络的结构及用反向传播算法对权值进行更新,最后我们会一步一步用C++对整个结构进行实现。
二、多层网络结构多层网络,顾名思义就是由多个层结构组成的网络系统,它的每一层都是由若干个神经元结点构成,该层的任意一个结点都与上一层的每一个结点相联,由它们来提供输入,经过计算产生该结点的输出并作为下一层结点的输入。 值得注意的是任何多层的网络结构必须有一输入层、一个输出层。下面的图结构是更形象的表示:
我们从图像中来再次说明多层网络的结构:上图是一个3层的网络结构,它由一个输入层、一个输出层和一个隐藏层构成,当然隐藏层的层数可以更多。图像隐藏层的结点ii与输入层的每一个结点相连,也就是说它接收了一组向量input=[x1,x2,x3,⋯,xn]input=[x1,x2,x3,⋯,xn]作为输入,同时与它相连的n条线代表了n个输入的权值。特别要注意的是图像隐藏层结点与输出结点还有一个红色的连线,它们代表了偏置,即w0w0。 那么结合上篇文章的内容,我们知道图像的i结点,它将输入与对应的权值进行线性加权求和,然后经过sigmoid函数sigmoid函数计算,把得到的结果作为该个结点的输出。
整个多层网络就是由一组输入开始,然后按每条连结线的权重,进行一直的向前计算。这里我们进一步对上面这个网络结构进行量化,以便后面实现:首先它是一个三层的网络结构,第一层是输入层,它本身没有接收输入,也没有连线进来;第二层有3个结点,并且有3*(4+1)根连结线,注意每个结点有一个偏置线;最后一层是输出层,它有4个结点,并且有4*(3+1)根连结线。所以说整个网络结构为[layer1,layer2,layer3][layer1,layer2,layer3],而每一层都是这样的结构:layer=[nodes,weights]layer=[nodes,weights]。
三、反向传播算法我们已经在上篇文章中讨论了单个结点用梯度下降的方法,可以去更新权值向量。而对于多层网络结构,我们也可以用类似的方法也推导整个网络的权值更新法则,我们把这种方法叫作反向传播算法,因为它是从输出层开始向前逐层更新权值的。 那么我们先从输出层考虑,还是先考虑整个输出误差是多少?不同与单个感知器单元(一个输出),多层网络结构具有多个输出,那么它的误差计算公式可以用LSM法则表示如下:
其中,outputsoutputs是网络输出单元的集合,DD还是代表所有训练样本空间,tkdtkd和okdokd是与训练样例dd和第kk个输出单元相关的预期值与输出值。 我们的目标是搜索一个巨大的假设空间,这个假设空间由网络结构中所有可能的权值构成。如果用几何的定义来思考,那么这个巨大的搜索空间构成了一个误差曲面,我们需要找到这个曲面上的最小值点。显然,梯度下降是我们的一个方法,我们通过计算曲面任何点的梯度方向,然后沿着反方向去改变权值,就会使误差变小。 回忆我们一篇文章讲到的随机梯度下降法则,我们将它应用在多层网络的反向传播算法中。我们每次只处理一个样本实例,然后更新各个权值,通过大量的样本实例逐渐的调整权值。那么对于每一次的训练样例dd来说,它的输出误差为:
对于输出层的结点上的连线权值,很明显它们可以直接影响到最终的误差,而隐藏层结点上的连结线权值只能间接的影响最后的结果,所以我们分两种情况来推导反向传播算法。 情况1:对于输出单元的权值训练法则: 我们知道每个结点前的所有连结线只能通过影响net(net的定义在上面的公式中)的结果来影响误差E,所以有:
我们把其中的(t−o)o(1−o)(t−o)o(1−o)看成与该个结点相关的误差项,并用符号δδ表示。 情况2:隐藏单元的权值训练法则 隐藏层中的任意结点上的连结线权值都是通过影响以它的输出作为输入的下一层(downstream)的结点而最终影响误差的,所以隐藏层的推导如下:
所以隐藏层单元权值更新法则为:
OK,上面内容就是反向传播算法,上面公式中有些中间推导步骤省略了,无非是一些链式法则求导的内容。不过就算没弄清楚整个推导过程也没有关系,只要按下面的算法来更新你的所有权值即可。
四、深入讨论
收敛性与局部最小值 正如前面所说的反向传播算法实现了一种对可能的网络权值空间的梯度下降搜索,它不断迭代从而减小训练样例目标值与网络输出之间的误差。但因为多层网络,误差曲面可能含有多个不同的局部极小值,我们的梯度下降可以收敛在这些极小值中。因此,对于多层网络,反向传播算法仅能保证收敛到误差E的某个局部极小值,不一定收敛到全局最小误差。 尽管缺乏对收敛到全局最小误差的保证,反向传播算法在实践中仍是非常有效的函数逼近算法。对很多实际中的应用,人们发现局部最小值的问题没有想像的那么严重。因为局部极小值往往是对于某个权值而言,些时其他权值未必也是极小值。事实上网络的权越多,误差曲面维数越多,也就越可能为梯度下降提供更多的“逃逸路线”让梯度下降离开相对该单个权值的局部极小值。 另外一个观点是,我们开始给权值初始化的值都非常小,接近于0,在这样小权值的情况下,sigoid函数可以近似的看为线性的,所以在权值变化的初期是不存在局部极小值问题的,而到了后期整个网络到了高度非线性的时候,可能这里的极小值点已经很接近全局最小值了。 多层网络的处理能力 很多人都会在这里发出疑问,什么类型的函数可以使用多层网络来表示呢?或者说什么样的分类问题可以用多层网络来表示呢?答案是:任意函数。任意函数可以被一个有三层单元的网络以任意精度逼近(Cybenko 1988)。但是值得注意的是,我们使用的梯度下降算法并没有搜索整个权值空间,所以我们很可能会漏掉那个最合适的权值集合。 归纳偏置 什么是归纳偏置?举个例子,假如我们有两个样本x1=[1,0,0,0]x1=[1,0,0,0]和x2=[0.8,0,0,0]x2=[0.8,0,0,0]并且我们认为它们属于同一类别,即如果把它们作为神经网络的输入,我们希望它们得到同样的输出。训练样本中只有这两个实例,但是如果我们需要得到x3=[0.9,0,0,0]x3=[0.9,0,0,0]的输出时,它的结果会和x1x1,x2x2的输出一样。神经网络的这种能力,我们称它为归纳偏置的能力,实际网络是在数据点之间平滑插值。 过度拟合 因为我们收集到的样本中有些样本可能由于我们分类错误等原因,造成了一个错误的样本用例,实际上神经网络对这种带有噪点的样本的适应性很强。但是在上面我们介绍的原理中,我们并没有规定权值迭代更新的终止条件,往往我们是设置了一个迭代次数来控制,也就有可能造成,在训练的后期那些权值是过度拟合那些噪点样本。这个问题没有统一的解决方案,现在比较常用的方法就是通过交叉验证,即在训练的同时,用一组校验校本进行测试,找出分类率回降的一个点,从而终于训练过程。
五、ANN的实现我们首先来定义几个类,用它们来分别表示神经网络结构中一些基本组件:整个网络(NeuralNetwork)、单层网络(NNlayer)、神经元结点(NNneural)、连接线(NNconnection)。 首先整个网络包含了一些参数,如层数、每层的结点数、迭代次数、每次实例的输出等,同时一个网络结构应该有的功能:设置参数、初始化网络、网络向前传播、反向传播、样本输入、训练等。 - class NNlayer;
- class NNneural;
- class NNconnection;
- class NeuralNetwork
- {
- private:
- unsigned nLayer; // 网络层数
- vector nodes; // 每层的结点数
- vector actualOutput; // 每次迭代的输出结果
- double etaLearningRate; // 权值学习率
- unsigned iterNum; // 迭代次数
- public:
- vector m_layers; // 整个网络层
- void create(unsigned num_layers,unsigned * ar_nodes); // 创建网络
- void initializeNetwork(); // 初始化网络,包括设置权值等
- void forwardCalculate(vector& invect,vector& outvect); // 向前计算
- void backPropagate(vector& tVect,vector& oVect); //反向传播
- void train(vector<vector>& inputVect,vector<vector>& outputVect); //训练
- void classifer(vector& inVect,vector& outVect); // 分类
- };
然后设计单层网络结构,我们需要一个指针成员来说明层与层之间的连接关系,同时每层网络是由大量的神经元结点构成,同时我们将权值向量作为了每一层的成员,为什么没有将权值与每个结点上的连接线捆在一起呢?那是因为到后面介绍到卷积神经网络的时候,你会发现很多结点可以共有一个权值。
- class NNlayer
- {
- public:
- NNlayer(){ preLayer = NULL; }
然后就是每个结点类和结点上的连接线,每个结点包含了一个输出和若干个连接线。这里连接线里保存是两个索引值,它表明条连接线的权重在整个权重向量中的索引与它连接的前面一层结点的索引。
- class NNneural
- {
- public:
- double output;
- vector m_connection;
- };
上面是基本的数据结构,而我们整个算法的核心就在于向前计算与反向传播来更新阈值,也就是函数forwardCalculate()和backPropagate()。 向前传播函数其实比较简单,注意第一层是输入层,它不接受来自其他层的输入,我们只需将它所有结点的输出设置为训练样本的特征即可。而反向传播函数,将最后一层与隐藏层区分开来,因为它们更新权值的法则不同,并且这个工作由每一层的backPropagate()函数来完成。 这里我们想起上篇文章中的一个例子,这里我们用多层的网络来再次去拟合那个目标函数,我们用了3层的网络结构,隐藏层设置了20层,而这里我们没有将结果设置为1维,而是用一个4维向量组成也就是与输入向量一致。下面是经过500迭代后产生的结果,并组我们最后以一组[0.01,0.99,0.001,-0.05]这样的输入来测试,我们预期的结果是[0,1,0,0],而程序得到的结果是。
六、结束语到这里,神经网络的基本结构和最常见的训练法则已经介绍完了,但是神经网络的发展已经有几十年的历史了,期间出现了各种的变种,让神经网络发展为了不同的种类,但它的基本思路都是不变的,正如下一篇文章即将介绍的卷积神经网络。
本文转载至:思维之际 |